Don't Ever Let the Facts Get in the Way of a Good Tale

A story about how we (allegedly) found an undocumented or reported “bug” in Delta Lake, how we “mitigated” it, only to realize there wasn’t a bug in the first place. We still developed a cool solution, and we love it!
You know how sometimes you’re hungry, but there’s not much to work with? You make a basic dish with whatever’s in the fridge (who said cucumber omelet is not a thing?), and it comes out surprisingly delicious, only to discover all the while you had everything you needed to make a fancy risotto. After you've finished cooking, you feel amazing simply because you created a wonderful recipe by yourself. This is kind of what happened to us as we were trying to solve a non-existing bug in Delta Lake.

Tables in Delta Lake provide ACID transactions, which implies data may be accessed and edited without causing corruption. However, there are significant assumptions and problems in this claim. In this post, we'll go through everything in detail: what is the table and format structure of our data lake; why and how we moved to Delta Lake (and why we love it!); what obstacles did we overcome (and believed they were bugs); how did we fix them; and how we learned we could have solved the problem right away by raising our thread's exceptions (and RTFM!).
TL;DR
- Delta Lake’s dataframe write API call turned out to be not thread-safe foolproof if the table does not exist yet;
- The same applies when multiple threads try to evolve the schema of an existing table
- The solution: Make sure that only one thread creates or modifies a table at a time, after which concurrent writing works flawlessly!
- Another (probably less efficient) solution: Just retry on exceptions until success.
- The best solution: RTFM and raise exceptions from threads in Python by calling result!
What does (part of) our data lake look like?
At @RecoLabs, we rely heavily on graphs to represent data. We also have a large number of distinct sorts of nodes and edges. As a result, each entity is represented by its own table. EmailAccount, CalendarEvent, and so on are examples of node tables, while InvitedTo, SentMessage, and so on are examples of edge tables.
Multiple sources are used to populate those tables at the same time: On a daily basis, raw data is pulled from SaaS platforms (such as GMail, GDrive, Calendar, and so on) and saved in an S3 (as JSON) bucket before being turned into the entities listed above (Also JSON at the time). For example, EmailAccount items can come from practically any of those services' extracted data, implying that we write to the same table from different sources.
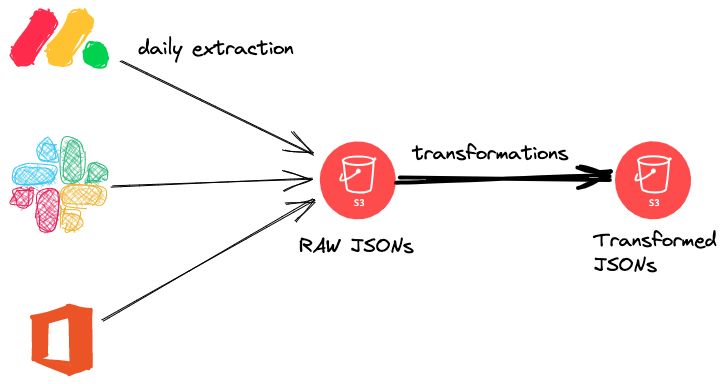
As a result, we need a technique to ensure the data in those tables is consistent. Furthermore, we want to ensure that if the schema of the entities changes, the tables would update as well (or alternatively crash if there is a schema incompatibility). Delta Lake is our guy! Not only does it not affect our formats significantly, but it also manages schemas, transactions, and concurrency. Or so we thought…
Coding through the migration to Delta Lake
Initially, our transformation code was built entirely in Python, and each raw JSON file taken from the SaaS was changed into a series of JSONs, each of which related to each of the entities in the original raw file. It's worth noting that, despite the fact that this method is embarrassingly parallel (each input file results in a single output file), it produces very small files, causing a performance hit on the readers of those tables later on.
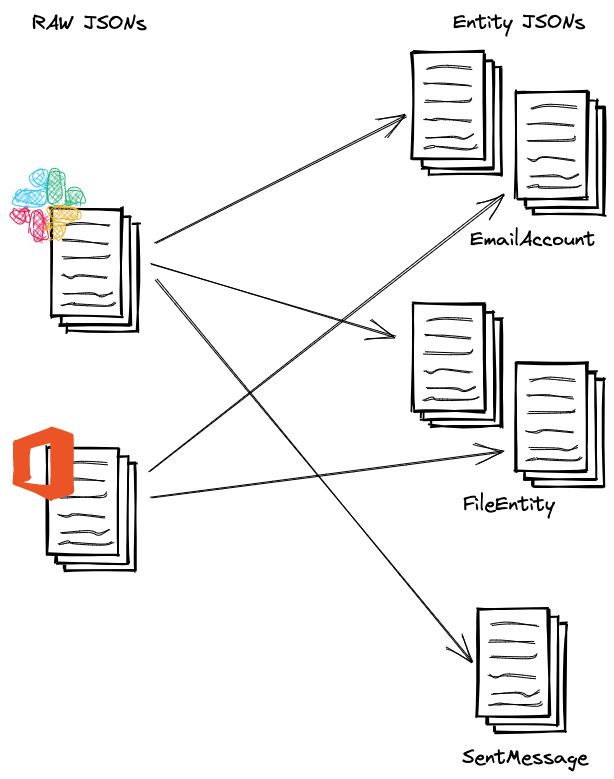
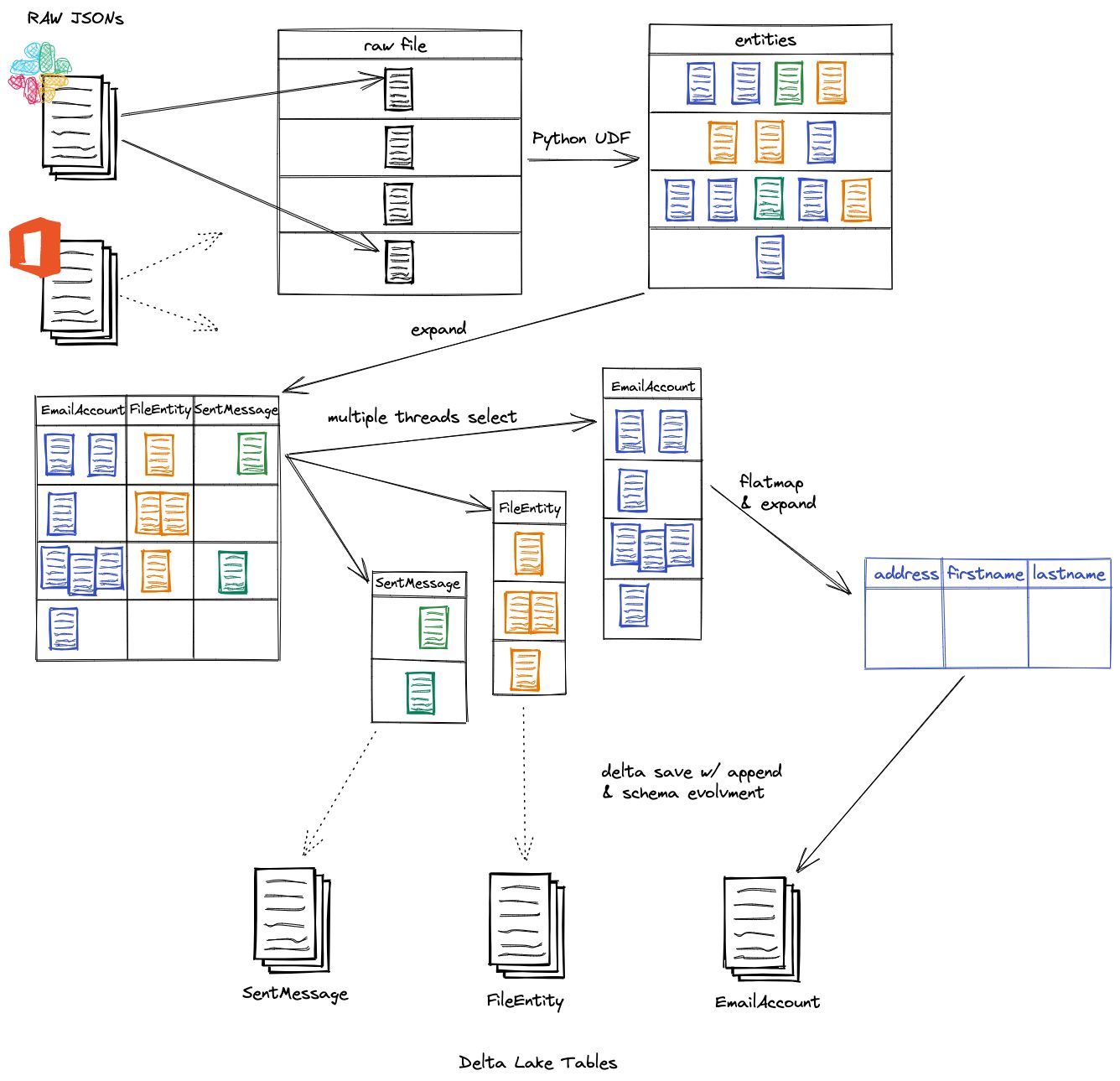
To use Delta Lake, we must convert the entities into Spark DataFrames, which necessitates rewriting some of the functionality in PySpark. That wasn't that difficult. Here it is in nutshell:
- Read the raw JSON files directory as a dataframe and run the Python function on the contents, which produces a list of all entities found in the raw file.
- Divide the results into columns, each of which corresponds to a distinct entity (note that each column is of the type Struct);
- Expand each of the aforementioned columns into its own dataframe, which can then be appended to a Delta Lake table (this step can be done in parallel!).
Another thing to keep in mind is that our entire product is deployed as a single-tenancy, which means that all of those tables are "duplicated" for each of our clients. As a result, the data lake for a new onboarding client is empty, and we must generate them from scratch during run time. Another scenario in which a new table must be created from scratch is when a customer configures a new SaaS for us to extract from. That includes a new type of entity.
Testing (and failing)
After the transformation outlined above, we run an aggregation suite that de-duplicates the entities and aggregates their fields according to a set of predefined rules (such as collecting all the titles of a CalendarEvent or setting the start and end time of the event to the ones from the last edit).
At this point, we've run a number of data quality tests (based on data samples of our own SaaS accounts).
After implementing the above, we ran those tests, and one actually failed! The test verified all nodes present in the edge tables (from and to) are present in the nodes tables (and vise-versa).
Investigating
The aggregation stage's code remained unchanged (save for reading Delta Lake instead of JSONs), so we decided it wasn't the source of the problem and crossed it off the suspect list.
Following further study, we discovered that different test runs result in different rows in the tables! That is to say, the issue is one of concurrency: For some reason, multiple threads add to the same dataframe that is stored to a Delta Lake table, causing it to collide. We arrived to the following findings about the Delta Lake dataframe write API after a little more tinkering:
- If the table does not exist yet, concurrent writes are not thread-safe.
- If the table does exist, concurrency works flawlessly.
As a result, we built an init function that looks over all possible entities and relationships before creating an empty Delta Lake dataframe with dummy data (we generate a dummy schema for all tables because we enable schema evolution anyway):
def _init_table_if_does_not_exist(self, table_name: str) -> None:
"""
Create a Delta Lake dataframe with a single row with a dummy value in the EXTRACTORS_PARTITION_COLUMN if the table doesn't already exist.
:param table_name: The name of the table to check and create.
:return: None.
"""
table_location = self.output_dir / table_name
if not table_location.exists():
self.spark.createDataFrame(
[("dummy_content", DUMMY_DATE_PARTITION)],
StructType(
[
StructField(TEMP_COLUMN_NAME, StringType()), # we need to add a dummy temporary column so we can partition the dataframe
StructField(EXTRACTORS_PARTITION_COLUMN, DateType()),
]
),
).write.partitionBy(EXTRACTORS_PARTITION_COLUMN).format("delta").save(table_location.as_uri())
self.initialized_tables.add(table_name)
def _init_all_possible_tables(self) -> None:
"""
Initialize the whole `Extracted` directory with all possible DeltaLake tables if they do not exist.
Initializing all the tables is necessary for Delta Lake's concurrent writes (the table creation is not thread safe).
:return: None
"""
possible_tables = get_possible_entities().union(get_possible_relations())
with ThreadPoolExecutor(max_workers=len(possible_tables)) as executor:
executor.map(self._init_table_if_does_not_exist, possible_tables)We did all of the modifications and writings in parallel after the table initializations. Then there was some cleanup to be done. In the code above, there is a dummy partition (1970-01-01) with a dummy column. Those should not be included in any of our final dataframes. Furthermore, if we didn't touch any empty dataframes throughout this run of the transformation step, we don't want them.
So we wrote some cleanup functions:
def _clean_written_table_schema(self, table_name: str) -> None:
"""
Clean a written table from the initialization rows and column.
The initialized table has a dummy partition and a dummy column that need to be removed.
Note: Because we are using Delta Lake those deletions are atomic. If you browse the underlying files
of the table you will still see the deleted partition. However, you can open the `_delta_log`
directory and see the deletion operation. This is done for the rollback in case of an issue.
:param table_name: The table to cleanup.
:return: None
"""
table_location = self.output_dir / table_name
current_written_df = self.spark.read.format("delta").load(table_location.as_uri())
if TEMP_COLUMN_NAME in current_written_df.columns:
TransformToModelStep._save_model_dataframe(
current_written_df.drop(TEMP_COLUMN_NAME).where(current_written_df[EXTRACTORS_PARTITION_COLUMN] != DUMMY_DATE_PARTITION),
table_location,
mode="overwrite",
overwrite_schema=True,
)
def _delete_table(self, table_name: str) -> None:
"""
Completely delete a given table.
:param table_name: The name of the table to delete.
:return: None
"""
shutil.rmtree(self.output_dir / table_name)
def _clean_output_dir(self) -> None:
"""
Clean up tables that were just initialized and written into and completely remove tables that we initialized but not touched.
Tables that were written and not initialized (as they existed before) or existent and untouched tables would not be modified.
:return: None
"""
initialized_and_written = self.written_tables.intersection(self.initialized_tables)
if initialized_and_written:
with ThreadPoolExecutor(max_workers=len(initialized_and_written)) as executor:
executor.map(self._clean_written_table_schema, initialized_and_written)
initialized_but_empty_tables = self.initialized_tables.difference(self.written_tables)
if initialized_but_empty_tables:
with ThreadPoolExecutor(max_workers=len(initialized_but_empty_tables)) as executor:
executor.map(self._delete_table, initialized_but_empty_tables)These functions totally remove initialized and untouched tables (by deleting their directories) and reconstruct the initialized and written tables without the dummy partition and column.
All good, right?

Furthermore, for some reason, schema merge (recall that we initialized a dummy table with only one dummy column) did not appear to be thread-safe, so we thought: Can we create a thread queue per model (each model is saved into a single Delta Lake table), where the first item in the queue runs alone and all the other tasks run in parallel after it finishes (similar to a soldier squad, where the first one ensures that the area is clear)?
This way, the first task constructs the Delta Lake directory with the correct schema (or merges a new schema to an existing table) without causing any disturbance, and all of the other writers are known to work fine in parallel after that!
So, instead of starting with one thread, we built a new ThreadPool that starts with one and then releases all the others to run:
from concurrent.futures import ThreadPoolExecutor # Future typing requires parameters at mypy level but doesn't run with Python 3.8
from typing import Any, Callable, Optional
class FirstBlockThreadPoolExecutor(ThreadPoolExecutor):
"""
A ThreadPoolExecutor that runs the first thread alone and then lets the other threads run like the original ThreadPoolExecutor.
"""
def __init__(self, max_workers: Optional[int] = None):
super().__init__(max_workers=max_workers)
# if the supplied `max_workers` is None, the super class chooses the number based on the host machine CPU
self.max_workers = self._max_workers # type: ignore
self.current_workers = 1
self._max_workers = self.current_workers
def submit(self, fn: Callable[..., Any], *args: Any, **kwargs: Any) -> Any:
future = super().submit(fn, *args, **kwargs)
if self.current_workers == 1:
future.add_done_callback(self._release_first_thread_block) # wait for the first thread to finish and adjust the number of threads
self.current_workers = self.max_workers
return future
def _release_first_thread_block(self, future: Any) -> None:
# The super class uses this object member to adjust the number of active threads.
# See https://github.com/python/cpython/blob/3.10/Lib/concurrent/futures/thread.py#L191
self._max_workers = self.current_workers
Not only do all tests pass now, but there is also much less code and much less writing!
- No initialization of all tables - each first thread in each pool writes, initializes it, or merges the schema out of the box.
- No rewrites and deletions at the end for cleanup of the init tables.
We are the champions (ARE WE?)
Not so fast… While writing this blog post we felt like we were missing something. How can Delta Lake fail so miserably in concurrent writing and not raise an exception? We then stumbled upon Concurrency control — Delta Lake Documentation which describes different exceptions that can occur when a transaction cannot be performed.
WAIT, WHAT? Did you say exceptions? We haven’t seen any 🤨… After a bit more investigation we found the reason was in ThreadPoolExecutor.submit function: if a thread throws an exception, it will not be raised unless Future.result function is called, which we didn’t use 🤦♂️. We’ve added result() calls to all submit() calls, and guess what?
delta.exceptions.ProtocolChangedException: The protocol version of the Delta table has been changed by a concurrent update. This happens when multiple writers are writing to an empty directory. Creating the table ahead of time will avoid this conflict. Please try the operation again.
Conflicting commit: {"timestamp":1638795307104,"operation":"WRITE","operationParameters":{"mode":Append,"partitionBy":["extraction_date"]},"isBlindAppend":true,"operationMetrics":{"numFiles":"1","numOutputBytes":"2536","numOutputRows":"66"}}
Refer to https://docs.delta.io/latest/concurrency-control.html for more details.
Yes, we are embarrassed, but at least we found the correct solution to the “problem” and we love our cucumber omelet because it is OUR cucumber omelet. Conclusion: Always raise or log errors - do not suppress them! Oh, and RTFM!